


Examples of the two challenges faced by fake news detection
Abstract
The easy sharing of multimedia content on social media has caused a rapid dissemination of fake news, which threatens society's stability and security. Therefore, fake news detection has garnered extensive research interest in the field of social forensics. Current methods primarily concentrate on the integration of textual and visual features but fail to effectively exploit multi-modal information at both fine-grained and coarse-grained levels. Furthermore, they suffer from an ambiguity problem due to a lack of correlation between modalities or a contradiction between the decisions made by each modality. To overcome these challenges, we present a Multi-grained Multi-modal Fusion Network (MMFN) for fake news detection. Inspired by the multi-grained process of human assessment of news authenticity, we respectively employ two Transformer-based pre-trained models to encode token-level features from text and images. The multi-modal module fuses fine-grained features, taking into account coarse-grained features encoded by the CLIP encoder. To address the ambiguity problem, we design uni-modal branches with similarity-based weighting to adaptively adjust the use of multi-modal features. Experimental results demonstrate that the proposed framework outperforms state-of-the-art methods on three prevalent datasets.
Method
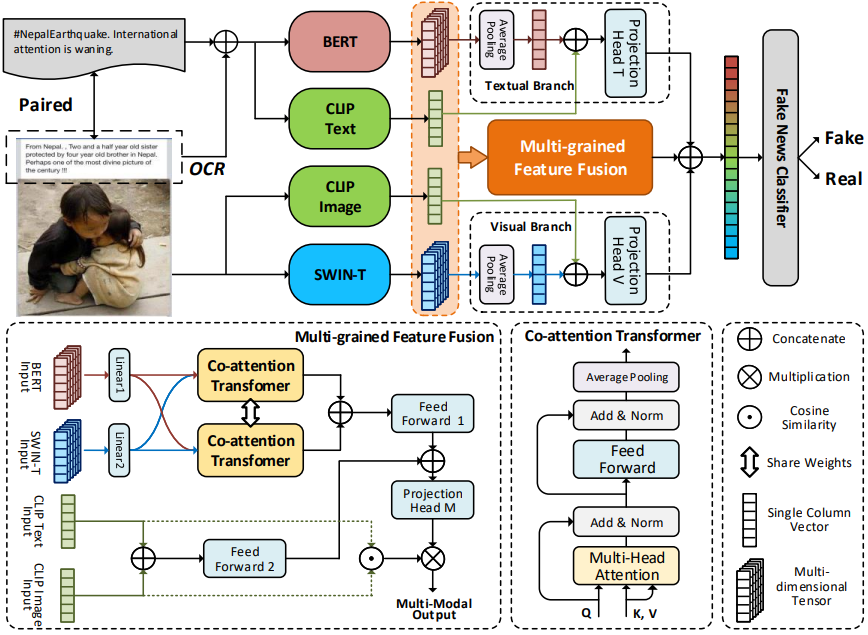
The network architecture of MMFN
We introduce the Multi-Granularity Multi-Modal Fusion Network (MMFN). The MMFN method integrates single-modal features and multi-granularity multi-modal fusion features to achieve more accurate fake news detection.
MMFN employs pretrained BERT and Swin Transformer (Swin-T) models to encode text and images separately, extracting fine-grained information at the token level. A pretrained CLIP model is utilized to encode coarse-grained features, capturing post-level semantic information and further resolving ambiguity issues.
We propose a multi-granularity multi-modal fusion module that fuses multi-modal features at different levels of granularity. In this module, fine-grained features are input into Co-Attention Transformer (CT) blocks to generate aligned fine-grained multi-modal features. Coarse-grained features are used to evaluate cross-modal correlations. Multi-modal fusion features typically reflect relevant information between two modalities but are susceptible to cross-modal ambiguity.
To address the decrease in representational capability of multi-modal fusion features when there is high cross-modal ambiguity, we design separate single-modal text and visual branches. To mitigate the impact of ambiguity, we use the cosine similarity of CLIP to assess cross-modal correlations, guiding the learning process of the classifier with these weights. When the CLIP similarity is high, it indicates strong cross-modal correlation, and more emphasis is placed on multi-modal fusion features. Conversely, if the similarity is low, the weight factors suppress multi-modal fusion features, and the decision process relies more on the single-modal branches.
If you like the project, please show your support by leaving a star 🌟 !