

An example of FND-CLIP detecting fake news on the Weibo dataset
Abstract
Fake news detection (FND) has attracted much research interests in social forensics. Many existing approaches introduce tailored attention mechanisms to fuse unimodal features. However, they ignore the impact of cross-modal similarity between modalities. Meanwhile, the potential of pretrained multimodal feature learning models in FND has not been well exploited. This paper proposes an FND-CLIP framework, i.e., a multimodal Fake News Detection network based on Contrastive Language-Image Pretraining (CLIP). FND-CLIP extracts the deep representations together from news using two unimodal encoders and two pair-wise CLIP encoders. The CLIP-generated multimodal features are weighted by CLIP similarity of the two modalities. We also introduce a modality-wise attention module to aggregate the features. Extensive experiments are conducted and the results indicate that the proposed framework has a better capability in mining crucial features for fake news detection. The proposed FND-CLIP can achieve better performances than previous works on three typical fake news datasets.
Method
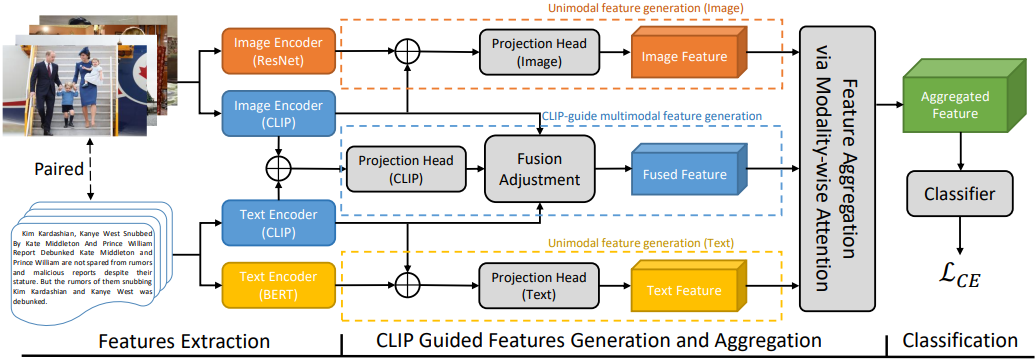
The network architecture of FND-CLIP
We propose FND-CLIP, a multi-modal fake news detection model that employs the CLIP model to address cross-modal ambiguity issues. In addition to utilizing CLIP, BERT, and ResNet pre-trained models for single-modal feature encoding, this article also employs CLIP to generate multi-modal features. These multi-modal features complement the single-modal ones, enhancing their semantic representations. CLIP leverages a vast dataset of image-text pairs for semantic extraction, eliminating emotions, noise, and irrelevant features associated with image and text matching.
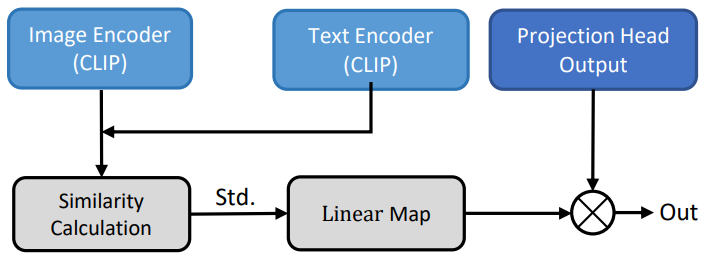
Fusion Adjustment Module
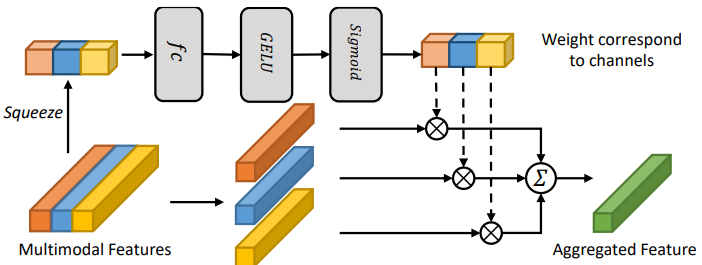
Modality Attention Module
When collaborating with single-modal features, we can comprehensively scrutinize news from various aspects. However, merely combining CLIP-based features into multi-modal features could lead to unreliable information due to the presence of additional ambiguous information within the features. To mitigate this ambiguity, we devised a fusion adjustment module. This module adjusts the strength of fused features by measuring the cosine similarity between text and image features provided by CLIP.
To further balance the impact of different modalities on news detection, drawing inspiration from SE-Net, we designed a modality attention module. This module employs two fully connected layers to learn relationships between modalities and applies these relationships to weight the feature values of each modality. This step allows the network to adaptively learn the importance of different modalities, thereby enhancing the network's performance.
If you like the project, please show your support by leaving a star 🌟 !