Experiment Document
In this benchmark, we adopt the training set in CNNSpot, which contains 360K real images from LSUN and 360K fake images generated by ProGAN. The whole dataset is divided into 20 different classes as shown bellow and every image is 256×256. For a fair comparison of the generalization, all baselines (except for DIRE-D) are trained over this dataset. DIRE-D is a pre-trained detector trained over ADM dataset and its checkpoint is provided by their official codes.




















Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen.
International Conference on Learning Representations, (ICLR). 2018.
Unconditional GAN; image size:256×256; test number:8.0k;
classes:airplane, bird, bicycle, boat, bottle, bus, car, cat, cow, chair, diningtable, dog, person, pottedplant, motorbike, tvmonitor, train, sheep, sofa, horse
Tero Karras, Samuli Laine, and Timo Aila.
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (CVPR). 2019.








Unconditional GAN; image size:256×256; test number:12.0k; classes:cat, car, bedroom
Andrew Brock,Jeff Donahue, and Karen Simonyan.
International Conference on Learning Representations, (ICLR). 2018.








Unconditional GAN; image size:256×256; test number:4.0k; classes:the same as ImageNet
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros.
Proceedings of the IEEE international conference on computer vision, (ICCV). 2017.








Conditional GAN; image size:256×256; test number:2.6k; classes:apple, horse, orange, summer, winter, zebra
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo.
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (CVPR). 2018.








Conditional GAN; image size:256×256; test number:4.0k; classes:person
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , (CVPR). 2019.







Conditional GAN; image size:256×256; test number:10.0k; classes:multi
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , (CVPR). 2020.








Unconditional GAN; image size:256×256; test number:15.9k; classes:car, cat, church, horse
Jevin West and Carl Bergstrom.








Conditional GAN; image size:1024×1024; test number:2.0k; classes:person
Prafulla Dhariwal and Alex Nichol.
Advances in neural information processing systems, (neurips). 2021.








Diffusion; image size:256×256; test number:12.0k; input sentences follow the template "photo of class", with "class" being substituted by ImageNet labels
JAlex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen.
Advances in neural information processing systems, (neurips). 2021.








Diffusion; image size:256×256; test number:12.0k; input sentences follow the template "photo of class", with "class" being substituted by ImageNet labels








Diffusion; image size:1024×1024; test number:12.0k; input sentences follow the template "photo of class", with "class" being substituted by ImageNet labels
JRobin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR). 2022.








Diffusion; image size:512×512; test number:12.0k; input sentences follow the template "photo of class", with "class" being substituted by ImageNet labels
JRobin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR). 2022.








Diffusion; image size:512×512; test number:16.0k; input sentences follow the template "photo of class", with "class" being substituted by ImageNet labels
Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, Bo Zhang, Dongdong Chen, Lu Yuan, and Baining Guo.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR). 2022.








Diffusion; image size:256×256; test number:12.0k; input sentences follow the template "photo of class", with "class" being substituted by ImageNet labels








StyleGAN; image size:512×512; test number:12.0k; input sentences follow the template "photo of class", with "class" being substituted by ImageNet labels
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen.








Diffusion; image size:256×256; test number:2.0k; input sentences follow the captions of COCO dataset
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Muller, Joe Penna, and Robin Rombach.








Diffusion; image size:1024×1024; test number:4.0k; input sentences follow the captions of COCO dataset
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros.
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (CVPR). 2020.
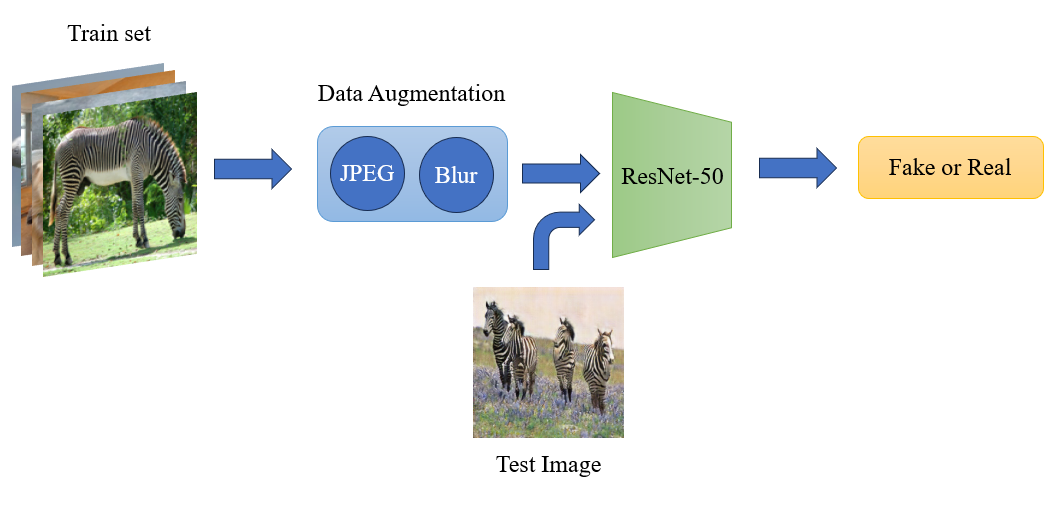
CNNSpot proposes a simple yet effective fake image detector. They adopt ResNet-50 as a classifier and observe that data augmentation, including JPEG compression and Gaussian blur, can boost the generalization of the detector, which means the detector can generalize well to unseen architectures, datasets, and training methods.

Zhengzhe Liu, Xiaojuan Qi, and Philip H. S. Torr.
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (CVPR). 2020.
GramNet abserves the difference between the texture of fake faces and real ones. Motivated by the observation, they aim to improve the generalization and robustness of the detector by incorporating a global texture extraction into the common ResNet structure.

Joel Frank, Thorsten Eisenhofer, Lea Sch ̈onherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz.
International conference on machine learning, (PMLR). 2020.
FreDect reveals that in frequency space, GAN-generated images exhibit severe artifacts that can be easily identified. Based on this analysis, they propose the frequency abnormality of fake images and conducts fake image detection from the frequency domain.
Yan Ju, Shan Jia, Lipeng Ke, Hongfei Xue, Koki Nagano‡, and Siwei Lyu.
2022 IEEE International Conference on Image Processing, (ICIP). 2022.
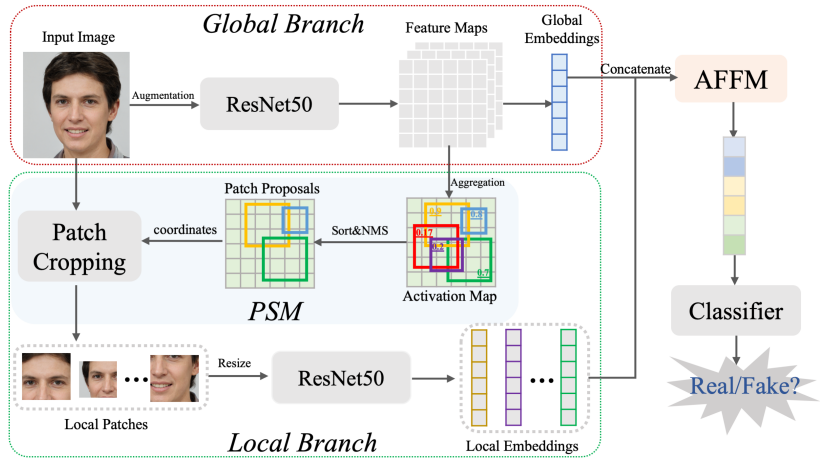
Fusing uses a two-branch model to extract global spatial information from the whole image and local informative features from multiple patches selected by a novel patch selection module. Global and local features are fused by the Multi-head attention mechanism. Then, a classifier is trained to detect fake image based on the fused feature.
Bo Liu, Fan Yang, Xiuli Bi, Bin Xiao, Weisheng Li, and Xinbo Gao.
European Conference on Computer Vision, (ECCV). 2022.
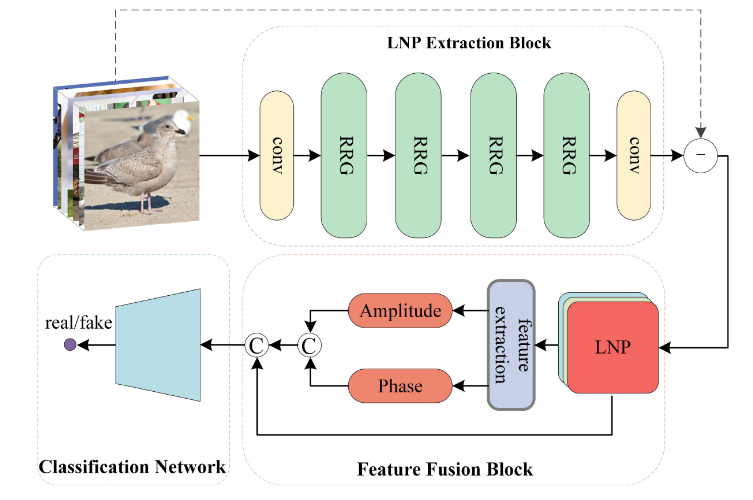
LNP observed that the noise pattern of real images exhibits similar characteristics in the frequency domain, while the generated images are far different. Therefore, it extracts the noise pattern of spatial images based on a well-trained denoising model. Then, it identifies fake images from the frequency domain of the noise pattern.
Chuangchuang Tan, Yao Zhao, Shikui Wei, Guanghua Gu, and Yunchao Wei.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR). 2023.
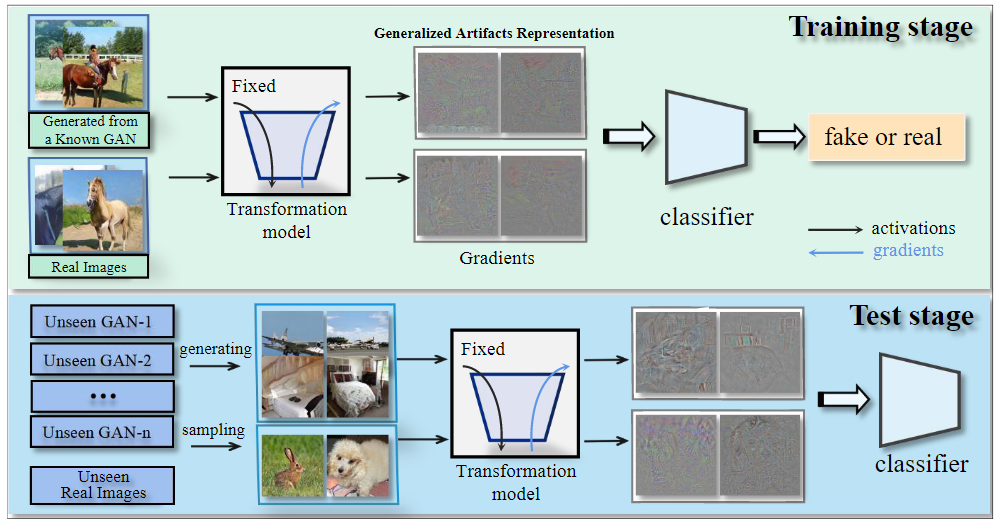
LGrad extracts gradient map, which is obtained by a well-trained image classifier, as the fingerprint of an GAN-generated image. This approach turns the data-dependent problem into a transformationmodel-dependent problem. Then, it conducts a binary classification task based on gradient maps.

Utkarsh Ojha, Yuheng Li, and Yong Jae Lee.
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR).2023.
UnivFD uses a feature space extracted by a large pre-trained vision-language model (CLIP:ViT-L/14) to train the detector. The large pre-trained model leads to a smooth decision boundary, which improves the generalization of the detector
Zhendong Wang, Jianmin Bao, Wengang Zhou,Weilun Wang, Hezhen Hu, Hong Chen, and Houqiang Li.
International Conference on Computer Vision, (ICCV). 2023.
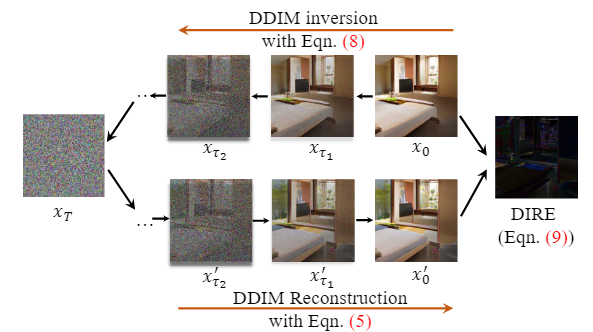
DIRE is dedicated to identifying fake images generated by diffusion-based images. They observe that diffusion-generated images can be approximately reconstructed by a diffusion model while real images cannot. Based on this observation, they leverage the error between an input image and its reconstruction counterpart by a pre-trained diffusion model as a fingerprint.
Nan Zhong, Yiran Xu, Zhenxing Qian, and Xinpeng Zhang.
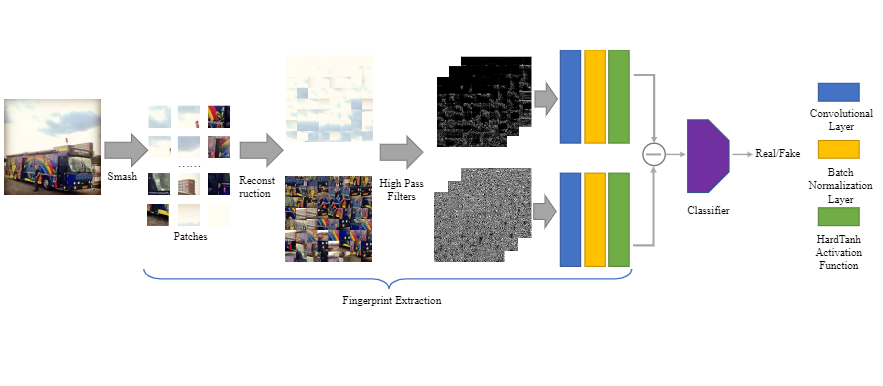
PatchCraft leverages the inter-pixel correlation contrast between rich and poor texture regions within an image. Pixels in rich texture regions exhibit more significant fluctuations than those in poor texture regions. Based on this principle, we divide an image into multiple patches and reconstruct them into two images, comprising rich-texture and poor-texture patches respectively. Subsequently, we extract the inter-pixel correlation discrepancy feature between rich and poor texture regions. This feature serves as a universal fingerprint used for AI-generated image forensics across different generative models.